
Продолжение. Конспект 1. Конспект 2.
Ceph
Ceph – распределённая масштабируемая система хранения с дизайном без единой точки отказа (single point of failure). Система разрабатывалась как открытый проект с файловой системой высокой масштабируемости до уровня эксабайт, и, по некоторым данным, даже выше, рассчитанная на работу на стандартном коммерчески доступном серверном оборудовании COTS (Commercial Off The Shelf). Ceph приобретает всё бóльшую популярность в облачных системах хранения данных.
В Ceph не используется корпоративная модель лицензирования и в ней нет ни одного набора функций «только для предприятий». С различными релизами Ceph можно ознакомиться здесь: https://ceph.com/category/releases/. Ceph входит в ядро открытой ОС Linux.
Архитектура Ceph
Основные принципы построения Ceph:
- Масштабируемость всех компонентов
- Отсутствие единой точки отказа
- Использование открытого ПО (Linux)
- Использование стандартного оборудования COTS (Commercial Off The Shelf)
- Автономность в управлении компонентами.
Любой формат данных (блок, объект или файл) сохраняется в Ceph в виде объекта внутри группы размещения кластера объектно-ориентированной системы хранения Ceph, которая реплицирует каждый объект по кластерам для повышения надежности. В Ceph объекты не привязаны к физическому местоположению узла хранения. Поэтому возможно линейное масштабирование СХД до уровня эксабайт.

Рисунок 11. Архитектура кластера СХД Ceph.
- Термины Ceph
- FUSE (File System in User Space) – файловая система в области пользователя.
- RADOS (Reliable Autonomic Distributed Object Store) — распределённая объектная СХД файловой системы Ceph, состоящая из автономных узлов хранения.
- RADOS Pool — несколько OSD, объединенных общим набором правил, например, политикой репликации. Представляет собой плоское (без подкаталогов) пространство имен для объектов.
- OSD (Object Storage Daemon) — процесс, обслуживающий каждый диск в RADOS-кластере.
- PG (Placement Group) — логическая группа, которая объединяет несколько объектов.
- CRUSH — алгоритм выбора места размещения объектов на OSD в RADOS-кластере.
- MON – ПО для мониторинга Ceph.
- MGR – ПО для администрирования Ceph, которое собирает информацию о состоянии со всего кластера в одном месте.
- MDS – ПО для метаданных Ceph (metadata software).
- LIBRADOS – библиотека, позволяющая приложениям обращаться непосредственно к RADOS с использованием языков C, C++, Java, Ruby, PHP.
- RADOGW (RADOS Gateway) — шлюз с API-интерфейсом REST между пользовательским приложением.
- RBD (RADOS Block Device), надёжное и полностью распределённое блочное устройство с клиентом на ядре Linux и драйвером KVM (Kernel-based Virtual Machine).
- Ceph FS – (Ceph File System) файловая система, совместимая с переносимым интерфейсом операционных систем POSIX (Portable Operating System Interface), который представляет собой набор стандартов, описывающих интерфейсы между операционной системой и прикладной программой, с клиентом ядра Linux и поддержкой FUSE.
- COTS (Commercial off the Shelf) — стандартное коммерчески доступное компьютерное оборудование.
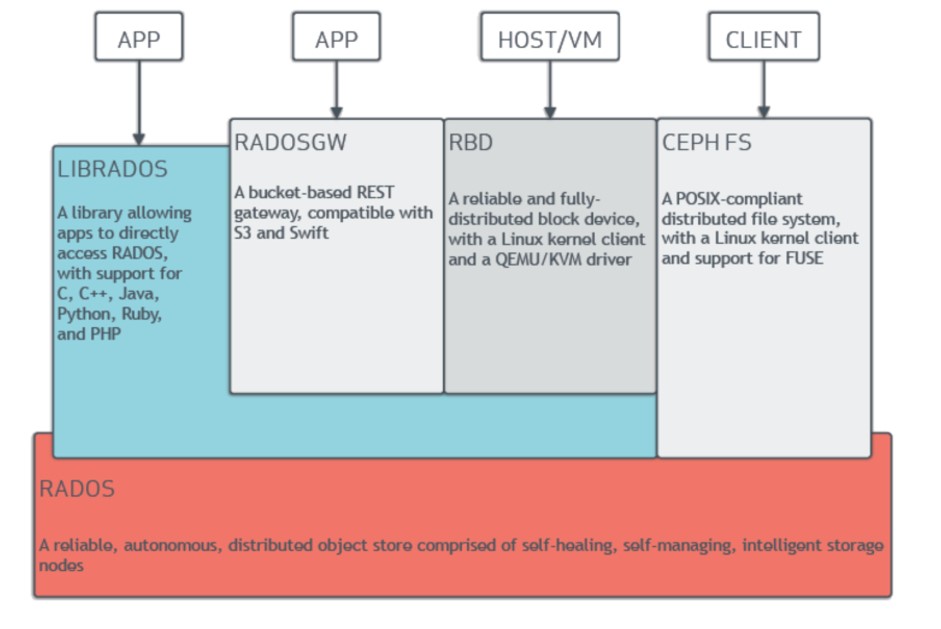
Рисунок 12. Архитектура файловой системы Ceph (источник: docs.ceph.com).
Применения Ceph
Ceph для клиента выглядит как обычная файловая система с папками и файлами, организованными по принципу иерархии.
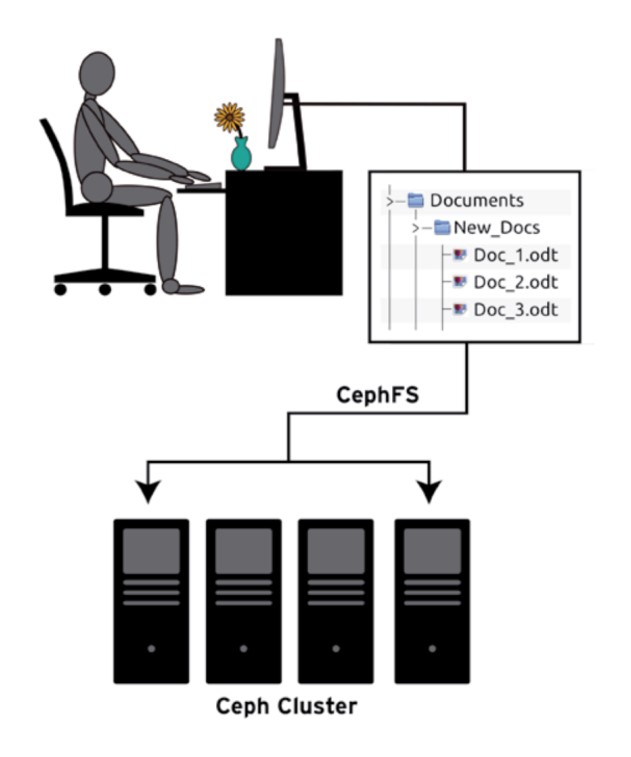
Рисунок 13. Интерфейс Ceph FS (источник: suse.tech).
Ceph реплицирует данные, за счёт чего файловая система устойчива к отказам при использовании обычного стандартного компьютерного оборудования COTS, которое не требует специального обслуживания или администрирования. Поэтому она хорошо подходит для организаций, которые не обладают экспертизой в ИТ, и в которых недостаточно средств для содержания штата ИТ-специалистов.
Ceph – это решение на базе открытого ПО (open source), как альтернатива коммерческим и частным решениям облачных систем и услуг хранения данных, которая хорошо подходит для образовательных и научных организаций.
Например, ряд университетов Австралии построили совместную распределённую программно-конфигурируемую СХД на основе файловой системы Ceph.
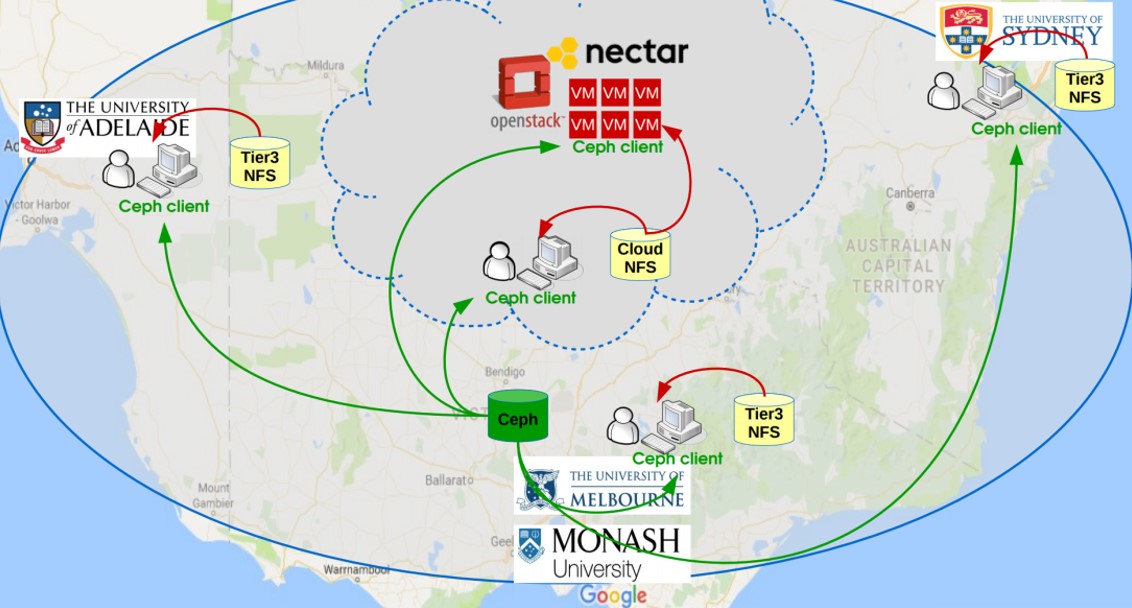
Рисунок 14. Применение Ceph FS для единой сети университетов Австралии (источник: https://indico.cern.ch/event/505613/contributions/2230911/attachments/1345227/2039428/Oral-v5-162.pdf).
Самый крупный заказчик Ceph – это Центр ядерных исследований CERN в Швейцарии, который использует объектную программно-конфигурируемую СХД на базе распределённой файловой системы Ceph для хранения и обработки огромных массивов данных (уровня петабайт) научных экспериментов, проводимых на адронном коллайдере.
Однако, как показывает опыт, Ceph может хорошо устанавливаться и запускаться даже на кластере из трёх компьютеров с пулом хранения в несколько Терабайт.
Результаты тестирования (https://www.mellanox.com/related-docs/whitepapers/wp_hadoop_on_cephfs.pdf), показывают, что CephFS работает так же, или превосходит распределённую файловую систему Hadoop (HDFS) для анализа больших данных. Это даёт возможность разворачивать кластеры Hadoop с различными приложениями на базе одной файловой системы без деградации характеристик или производительности. Более того, динамическая масштабируемость ресурсов вычислений и хранения может быть применена и для специфических приложений Hadoop.
Lustre
Lustre – это кластерная архитектура для СХД, центральным элементом которой является файловая система Lustre, работающая на ОС Linux и обеспечивающая POSIX-интерфейс для файловой системы UNIX.
Распределённая архитектура СХД Lustre используется для различных видов кластеров: например, для кластеров высокопроизводительных вычислений HPC (high-performance computing) в мировом масштабе, в состав которых может входить до нескольких десятков подчинённых кластеров, каждый из которых может содержать десятки тысяч клиентских систем, с объемами данных уровня Петабайт и с пропускной способностью уровня ГБ/с.
Применения Lustre
Lustre способна масштабировать ёмкость и производительность практически до любых требуемых величин, устраняя надобность в развёртывании многих отдельных файловых систем в каждом компьютерном кластере, а также необходимость копировать данные из одного кластера в другой, где они также могут понадобиться. Кроме агрегирования ёмкости хранения многих серверов, пропускная способность ввода-вывода также агрегируется и масштабируется при добавлении серверов, в том числе, в динамическом режиме.
Lustre лучше всего подходит для сценариев, когда требуется больше ёмкости, чем есть в одном севере. Хотя, есть много применений, когда Lustre работает лучше других систем на одном сервере.
Lustre также не очень подходит для сетевых моделей «peer-to-peer», где клиенты и серверы работают на одном узле хранения, и каждый занимает небольшую область ёмкости, из-за недостаточной репликации на уровне ПО Lustre. При этом, если один клиент или сервер отказывает, то данные этого узла будут недоступны, пока узел не перезапустится.
Характеристики Lustre
Lustre может быть развёрнута на самых разнообразных конфигурациях, которые могут хорошо масштабироваться.
Таблица 1. Параметры файловой системы Lustre
| Параметр | Практическое значение в настоящее время | Известный масштаб использования |
| Масштабирование числа клиентов | 100-100000 | Более 50000 клиентов, многие из которых имеют от 10000 до 20000 узлов |
| Производительность клиента | Один клиент: I/O: 90% полосы пропускания сети Агрегированные клиенты: I/O: 10 ТБ/с | Один клиент: I/O: 4,5 ГБ/с (FDR IB, OPA1), 1000 операций с метаданными в секунду Агрегированные клиенты: I/O: 2.5 ТБ/с |
| Масштабируемость OSS (Object Storage Servers) и OST (Object Storage Targets) | Один OSS: 1-32 OST на OSS Один OST: 300 млн объектов, 256TiB на OST (ldiskfs) 500 млн объектов, 256TiB на OST (ZFS) Число OSS: 1000 OSS, в каждой из которых до 4000 OST | Один OSS: 32 x 8 TiB OST на OSS (ldiskfs), 8 x 32TiB OST на OSS (ldiskfs) 1 x 72TiB OST на OSS (ZFS) Число OSS: 450 OSS с 1000 4TiB OST 192 OSS с 1344 8TiB OST 768 OSS с 768 72TiB OST |
| Производительность OSS | Один OSS: 15 ГБ/с Агрегация серверов: 10 TБ/c | Один OSS: 10 ГБ/с Агрегация серверов: 2,5 TБ/c |
| Масштабируемость MDS (Metadata Service) и MDT (Metadata Target) | Один MDS: 1-4 MDT на MDS Один MDT: 4 млрд файлов, 8TiB на MDT (ldiskfs) 64 млрд файлов, 64 TiB на MDT (ZFS) Количество MDS: 256 MDSs, with up to 256 MDTs | Один MDТ: 3 млрд файлов Количество MDS: 7 MDS с семью MDT на 2 TiB в продуктивном использовании 256 MDS с 256 MDT на 64G iB в тестировании |
| Производительность MDS | 50000 операций создания в секунду 200000 операций с метаданными в секунду | 15000 операций создания в секунду 50000 операций с метаданными в секунду |
| Стабильность файловой системы | Один файл: Максимальный размер файла 32 PiB (ldiskfs), 263 байт (ZFS) Агрегация: Пространство 512 PiB, 1 триллион файлов | Single File: Максимальный размер Несколько терабайт TiB Агрегация: Пространство 55 PiB, 8 млрд файлов |
Компоненты Lustre
Базовая конфигурация компонентов Lustre показана на рисунке.
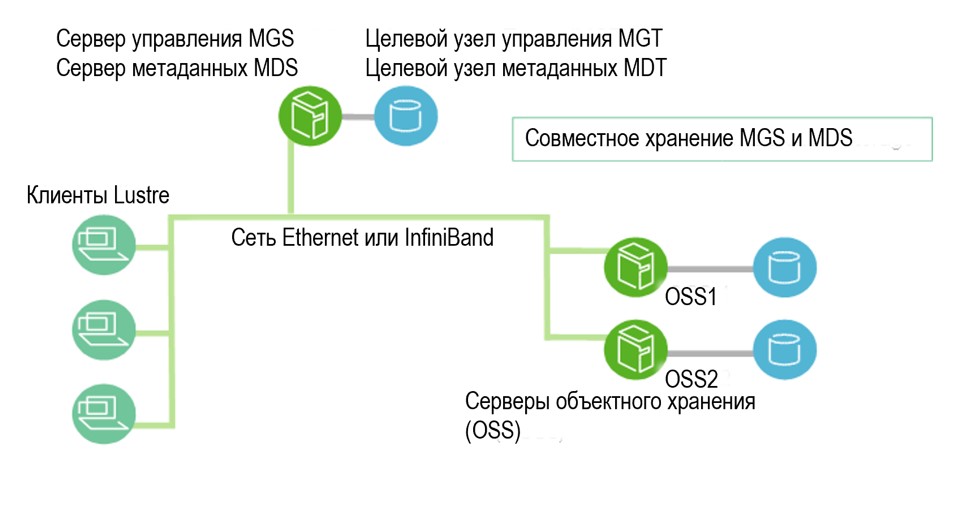
Рисунок 15. Базовая конфигурация компонентов Lustre.
- Сервер метаданных MDS (Metadata Server). Благодаря MDS, метаданные, хранимые в одном или больше MDT доступны для клиентов Lustre. Каждый MDS управляет именами и директориями в файловой системе (системах) Lustre и обеспечивает запросы сети на обработку одного или более местных MDT.
- Целевой узел метаданных MDT (Metadata Targets). Каждая файловая система имеет по крайней мере один MDT. Он хранит метаданные (имена файлов, директории, разрешения и форматы файлов) в СХД, которая присоединена к MDS. MDT на одном целевом узле хранения может быть доступен для многих серверов MDS, хотя только один MDS может иметь доступ к этому MDT в какой-то момент времени. Если этот MDS отказывает, то резервный MDS берёт на себя обслуживание MDT и делает его доступным для клиентов. Такая операция называется MDS failover.
В распределённой среде пространства имен DNE (Distributed Namespace Environment) поддерживаются множество MDT. Кроме того, первичный MDT, который содержит корневой каталог файловой системы (filesystem root) может добавлять дополнительные узлы MDS, каждый со своими MDT, и таким образом поддерживать деревья субдиректорий в файловой системе.
Начиная с версии Lustre 2.8 DNE также позволяет файловой системе распределять файлы по многим узлам MDT. Директория, которая распределена на множество MDT, называется striped directory («располосованная директория»).
- Сервер объектного хранения OSS (Object Storage Servers). OSS управляет операциями ввод-вывода данных и сетевых запросов для одного или больше OST. Обычно, сервер OSS обслуживает от двух до восьми OST, объёмом до 16 TiB каждый. Типичная конфигурация – MDT на отдельном узле, два или больше OST на каждом узле OSS и клиент на каждом из множества серверных узлов.
- Целевой узел объектного хранения OST (Object Storage Target) пользовательские файлы сохраняются в одном или более объектах. Каждый объект сохраняется на отдельном узле OST файловой системы Lustre. Пользователь может конфигурировать число объектов на файл и может оптимизировать производительность под рабочую нагрузку.
- Lustre. Клиенты Lustre – это узлы серверов, систем визуализации или рабочих станций, на которых работает клиентское ПО Lustre.

Рисунок 16. Масштабирование ёмкости и производительности Lustre может делаться добавлением OSS и OST (источник: http://wiki.lustre.org).
Клиентское ПО Lustre обеспечивает интерфейс между виртуальной файловой системой Linux и серверами Lustre. Оно включает клиент управления MGC (management client) и множество клиентов объектного хранения OSC (object storage clients), каждый из которых соответствует каждому OST в файловой системе.
Логический том объекта LOV (logical object volume) агрегирует клиентов OSC, чтобы обеспечить прозрачный доступ через все узлы объектного хранения OST. Таким образом, каждый клиент с установленной файловой системой Lustre может видеть единое, когерентное и синхронизированное пространство имён. Множество клиентов могут записывать и просматривать разную информацию в одном и том же файле одновременно.
Логический том метаданных LMV (logical metadata volume) агрегирует целевые узлы метаданных MDТ, чтобы доступ ко всем MDT делался точно также, как LOV поступает для доступа к файлу. Это позволяет клиенту видеть дерево директорий на многих MDT единое, когерентное пространство имён и «располосованные» директории (striped directories) доступны пользователям и приложениям как единая видимая директория.
С точки зрения пользователя
С точки зрения пользователя, основным преимуществом распределённых файловых систем является то, что они предоставляют доступ к существенно большему объёму хранения, чем физически может быть присоединено к системе пользователя.
Однако, доступ к общей для многих пользователей системе хранения может сопровождаться конфликтами, поскольку нет универсального метода доступа к распределённым СХД. Классический путь решения этой проблемы – глобальное пространство имён (global namespace), как единая директория, через которую вся распределённая файловая система становится доступной для пользователей.
К сожалению, многие распределённые файловые системы построены на фиксированных ссылках (hardwired references) на точки монтирования отдельных файловых систем пользователей и приложений. Менять эти ссылки достаточно сложно.
В отличие от таких файловых систем, Lustre обеспечивает global namespace, которое может быть легко разбито на директории в существующих файловых системах Linux. После монтирования Lustre, любой аутентифицированный клиент может получить доступ к файлам внутри неё по единому пути и имени файла. Однако, начальная точка монтирования Lustre при этом не является фиксированной и не должна быть одинаковой в каждой клиентской системе.
Если нужно, единая точка монтирования для Lustre может быть задана административно, путём монтирования файловой системы Lustre в одинаковой директории на каждой клиентской системе, но это не является обязательным требованием.
