
В предыдущией публикации о тенденциях телекома в 2022 году упоминался Искусственный Интеллект с нейросетью, работающей по методу «few-shot learning» – обучение по ограниченному числу попыток. Сегодня об этом подробнее.
Как программам, таким как нейросеть OpenAI GPT-3, удаётся отвечать на вопросы, которые не предполагают единственного ответа, или писать стихи в определённом стиле, в то время как эта нейросеть никогда не программировалась специально для таких задач?
Такое становится возможным вследствие того, что человеческий язык имеет некоторые статистические свойства, которые дают нейросети возможность «ожидать неожиданного», как указано в новом отчёте DeepMind, подразделения Google по Искусственному Интеллекту.
Естественный язык, с точки зрения статистики, имеет свойства «многозначности», например, слова, которые могут означать сразу несколько понятий. Например, слово «банк», что может означать как финансовое учреждение, так и название карточной игры, или отмели у берега. Есть и слова, которые звучат совершенно одинаково, но пишутся по-разному и означают разные понятия. Например, английские слова «here» (здесь) и «hear» (слышать) звучат совершенно одинаково и их можно правильно определить только в контексте сказанного. В китайском языке таких слов, значение которых можно понять только из контекста, особенно много.
Эти свойства языка описаны в недавно опубликованной статье «Data Distributional Properties Drive Emergent Few-Shot Learning in Transformers» учёных DeepMind Стэфани Чан (Stephanie C.Y. Chan), Адамом Санторо (Adam Santoro) и др.
Как программы, такие как GPT-3, решают задачи, где нейросеть сталкивается с запросами, на которые она ранее не обучалась в явном виде (supervised training)? Такие ситуации получили название «few-shot learning» – обучение по ограниченному числу попыток.
Например, GPT-3 может отвечать на многозначные вопросы без предварительного обучения таким формам запросов, просто попросив пользователя дать пару вариантов ответов на такие неопределённые запросы. Далее GPT-3 может действовать по аналогии самостоятельно.
В GPT-3 используются т.н. большие языковые модели, основанные на рекомбинационной трансформации (transformer-based language models), т.е. модели глубокого обучения (deep learning model), в которых используется механизм «самоизучения» (self-attention), который может дифференцированно взвешивать важность каждой части вводимых данных. Такие модели используются, в основном, в системах обработки естественных языков NLP (natural language processing), или в разнообразных применениях компьютерного зрения CV (computer vision). Эти модели могут выполнять алгоритмы few-shot learning (известные также как in-context learning), без supervised learning на подобных задачах.
В основе языковых программ Google – GPT-3, а также BERT (Bidirectional Encoder Representations from Transformers) лежит популярная нейросеть, которая так и называется – «Transformer».
Авторы исследования DeepMind предположили, что такие большие программы языковых моделей ведут себя подобно другому типу программ машинного обучения, которые называются Meta-learning. Программы Meta-learning, исследованные в DeepMind, могут моделировать образы поведения (patterns) моделей данных, которые применимы для различных больших наборов данных. Такие программы обучены моделированию распределения значений слов или символов не одного набора данных, а многих наборов.
При этом, различия значений одного слова порождают различные наборы данных контекстных вариантов использования этого слова в разных значениях, но у этих вариантов оказывается много общего в структуре самой модели.
Таким образом, натуральный язык – это нечто лежащее посередине между явно-обучающими данными (supervised learning) с регулярными паттернами (образцами использования слов) и мета-обучением (meta-learning) с множеством наборов различных данных.
В методе supervised learning, объекты (слова) и метки объектов (item-label, по сути, значения слов) являются фиксированными. В тоже время, редко в встречающихся распределениях (long-tailed distribution) встречаются слова в значениях, которые используются весьма нечасто, и только в т.н. «контекстных окнах» (context windows). Однако в этих окнах они могут встречаться гораздо чаще, чем в обычном контексте. Именно в таких ситуациях работает метод few-shot meta-training, где метка (значения) объектов могут меняться в каждом эпизоде.
Для проверки гипотезы, учёные DeepMind, как ни странно, не стали работать именно с языковыми задачами, а стали обучать нейросеть Transformer на решение визуальной задачи под названием Omniglot, которая была представлена в 2016 году исследователями Университета шт. Нью-Йорк, Carnegie Mellon и MIT. Типовая задача Omniglot заставляет программу распознавания образов предписывать привольные классификационные метки для 1623 рукописных символов, глифов (glyph).
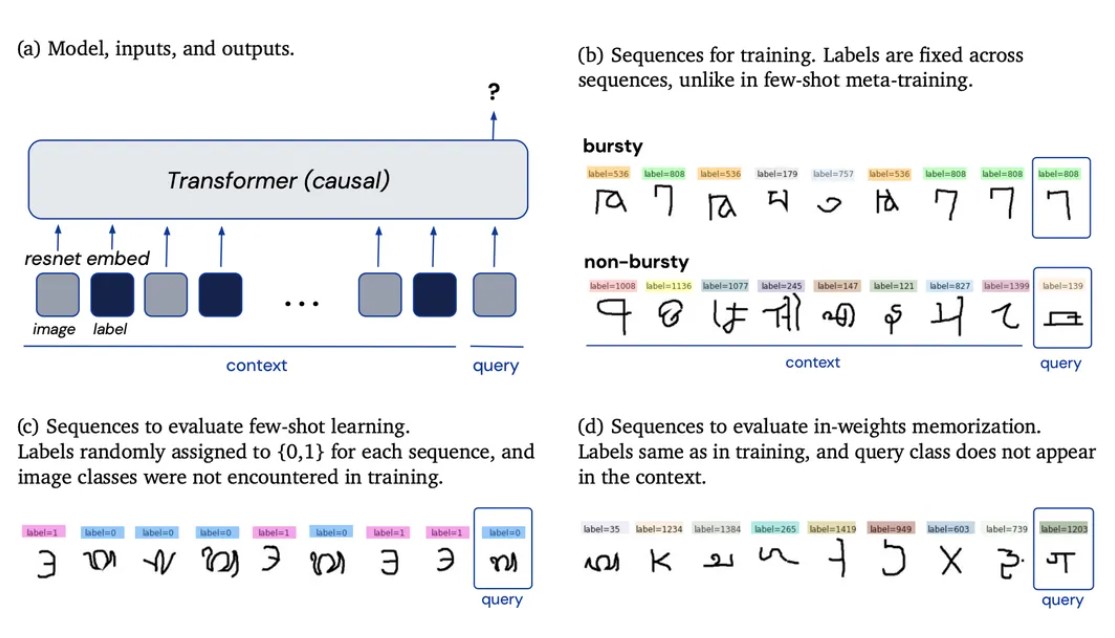
Экспериментальная таблица глифов в исследовании Deep Mind.
В процессе исследования выяснилось, что в случае множественных меток для данного глифа нейросеть работает лучше при использовании метода обучения по ограниченному числу попыток (few-shot learning). Учёные обнаружили, что рост фактора многозначности (‘polysemy factor’), т.е. меток, назначенных для каждого слова, также повышает эффективность метода few-shot learning.
Другими словами, чем сложнее задача выявления общих значений, тем лучше работает few-shot learning. Поэтому, платформа GPT-3 может чаще распознавать нетрадиционные и нечасто встречающиеся контексты и ситуации использования того или иного слова, тем самым шансы на имитацию того, что пользователю отвечает настоящий человек, а не система ИИ, значительно повышаются.

Уведомление: Тенденции телекома в 2022 году (1) | Telecom & IT