
Когда в 1960-х годах советского (после 1991 г. – украинского) профессора 3. Л. Рабиновича (1918 – 2009) спросили о будущем компьютеров, он ответил примерно так: «Перспективу развития многопроцессорных вычислительных систем я представляю себе в виде огромного поля памяти, на котором, как коровы, пасутся процессоры». Профессор Рабинович был одним из первых авторов концепции вычислений в памяти, опередив IBM (проект Future Systems 1970-х) с той же идеей, почти на 10 лет.
Однако, как это часто бывает в России, затем в СССР (и теперь опять в России, Украине и пр.), концепция осталась на уровне концепции, практическая реализация которой состоялась в другой стране.
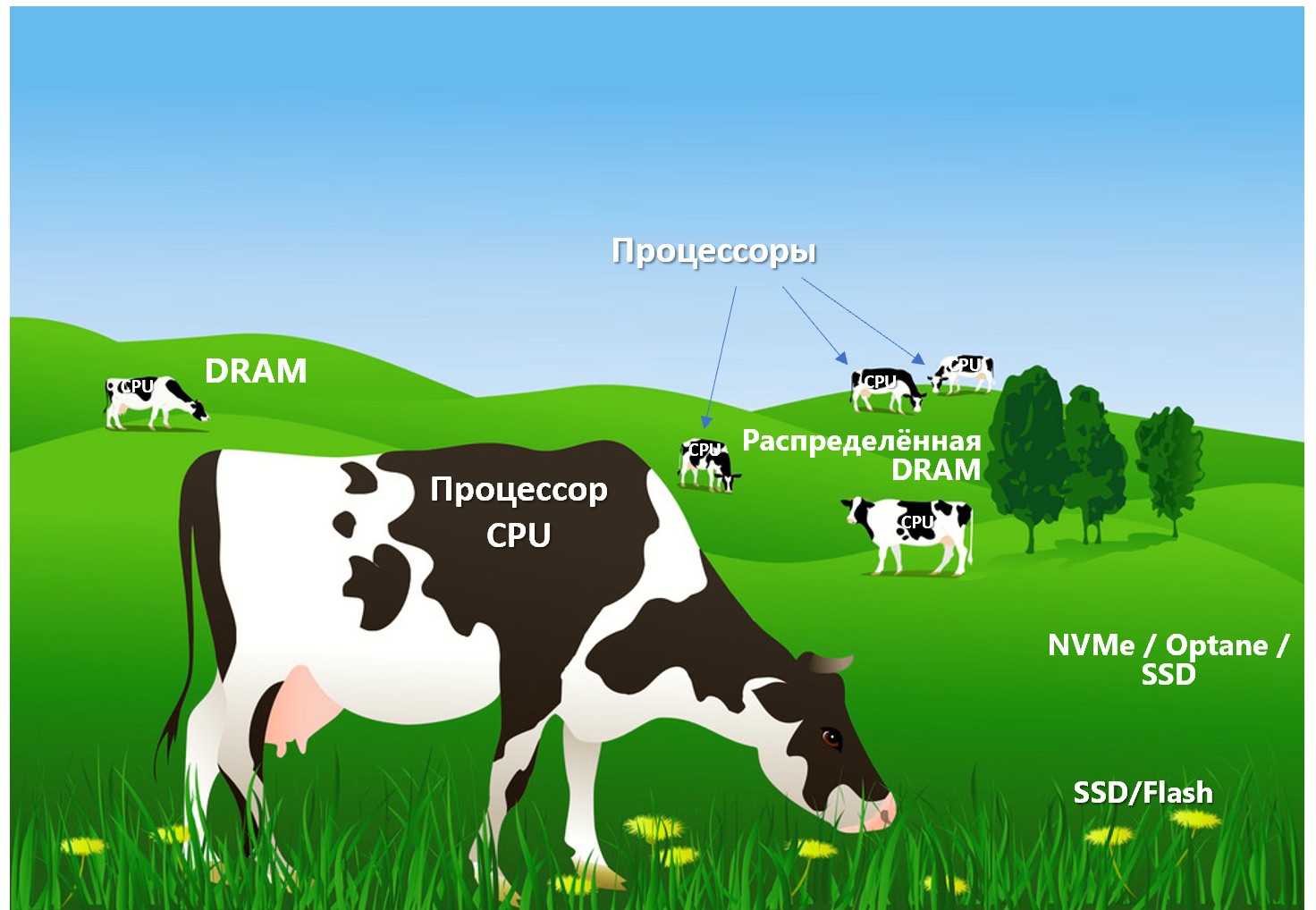
Так и теперь, эта концепция получила своё воплощение в проекте VMware под названием Project Capitola. Он представляет собой расширение всем ИТ-специалистам известного серверного гипервизора ESXi, который ранее мог виртуализовывать только вычислительные ресурсы. Однако, ресурсы оперативной памяти до сих пор виртуализовать не удавалось.

Гипервизор памяти Capitola компании VMware предполагает наличие серверного гипервизора ESXi и платформы виртуализации vSphere. Он должен управлять всеми видами памяти: с различным быстродействием и расположением: оперативной памяти DRAM, persistent-памяти PMEM, или SSD/flash и пр. И при этом, операционной системе не нужно знать, какие данные в какой памяти располагаются физически, для процессора CPU они предоставляются как единое «поле памяти». То есть, именно так, как это и задумывал профессор Рабинович.
На первом этапе проекта VMware пока удалось реализовать только виртуализацию памяти в пределах лишь одного серверного кластера и лишь ближайшего к ОЗУ слоя persistent-памяти.
Однако, тестирование показало, что уже одно это дало существенного снижение требуемой для оперативной памяти полосы пропускания, а это означает, что производительность такого кластера намного повышается.
Теперь на очереди – вертикальное масштабирование виртуализация памяти по всем слоям иерархии ОЗУ – СХД, а также горизонтальная масштабирование с создание единой фабрики памяти в масштабах распределённых дата-центров.
Если этот проект увенчается успехом, то в дата-центрах скоро мы не увидим отдельных стоек с серверами, стоек или полок с СХД, либо в сетевым оборудованием. А увидим полки с ресурсами CPU, полки с ресурсами памяти и СХД. Причем, два последних вида ресурсов будут представлять собой единое «поле памяти», именно такое, о котором мечтал профессор З.Л. Рабинович.
И всё это будет сшито между собой в единую «сетевую фабрику» (Network Fabric).


Вы молодец!
НравитсяНравится